
人工智能助手的时代越来越近:与数字面孔和化身的交互正在迅速成为我们日常生活中不可或缺的一部分。这些数字面孔在复制真人的真实感方面能走多远?从微软研究院刚刚开发的创新人工智能模型VASA-1来看,还很遥远。 在这里您可以找到该论文。
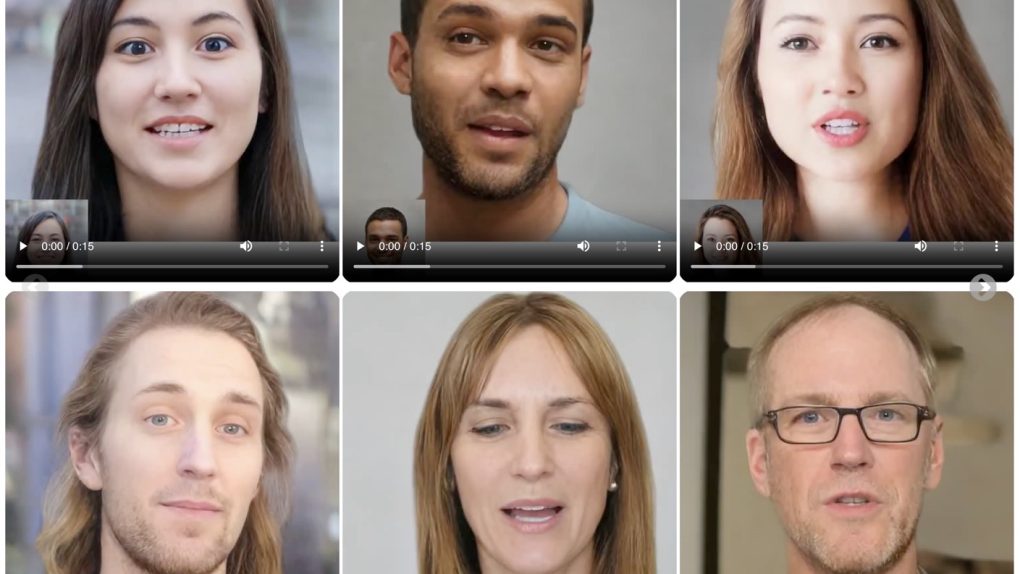
VASA-1 可以从单个图像和音频文件实时生成超逼真的说话面孔视频。它将突破创建数字化身的可能性界限,其应用范围从视频通话到娱乐内容,再到改善听力障碍人士的无障碍环境。

VASA-1,前所未有的真实感
VASA-1 真正具有革命性的是它能够达到的真实感水平。该人工智能模型生成的视频与真人的视频几乎没有区别。
这是通过一系列创新功能实现的。首先, VASA-1 提供嘴唇运动和音频之间的完美同步。 无论使用何种语言或是否存在背景噪音,化身的嘴唇都会与所说的话完美同步地移动,从而产生令人惊讶的真实感效果。
此外,VASA-1 能够捕捉和再现各种面部表情, 从最微妙的细微差别到最明显的情感。这为生成的头像和“数字人“。
最后,头部运动以自然流畅的方式产生, 有助于给人一种在真人而不是静态图像面前的印象。

实时生成、高质量
我发现 VASA-1 实时生成这些超逼真视频的能力令人印象深刻。目前它的分辨率为 512x512 像素,速度高达每秒 40 帧,但它们是实时说话的化身,没有延迟或中断。
这为许多创新应用铺平了道路。例如,VASA-1 可用于为视频通话创建个性化头像,使虚拟交互更具吸引力和真实性。它还可用于在视频游戏中生成交互式角色,或通过虚拟演示者创建教育和娱乐视频内容。
提高可及性
VASA-1 最有趣的潜在应用之一涉及可访问性。通过从音频文件生成说话面孔的视频,该人工智能模型可用于为听力障碍人士创建可访问的视频内容版本。
想象一下,能够观看演讲或讲座,演讲者头像清晰地与音频同步发音。这可以使内容对于有听力障碍的人来说更容易使用,为学习和参与开辟新的可能性。
VASA-1 和虚拟通信的未来
微软研究人员并不满意,已经在努力进一步提高 VASA-1 的性能。未来,我们可以期待更高质量、更流畅、分辨率更高的会说话的化身。更不用说电影和动画的时间和成本:它们将完全改变。
你们还记得那部开创性的电视剧《最大净空高度“?在那里,一位真正的记者作为虚拟化身“复活”。三十年前的一个富有远见的系列,很快就会被事实完全超越。随着 VASA-30 和类似技术的进步,虚拟通信和面对面交互之间的界限可能会变得越来越模糊。
当然,这种观点也引发了伦理和社会问题。制定指导方针和法规以确保负责任和透明地使用这些技术、保护隐私并防止潜在的滥用(例如创建深度伪造品)非常重要。
也就是说,VASA-1 等模型的潜在好处是巨大的。
从更具吸引力的沟通到增强的学习,从更具互动性的娱乐到更大的可访问性,这些应用程序是巨大且前景广阔的。
VASA-1 让我们对未来有了一个令人着迷的一瞥,在这个未来中,虚拟通信将与面对面的通信越来越难以区分。在未来,超现实的化身不仅可以传达文字,还可以传达情感、表情和存在。未来,物理距离将不再是障碍,内容的可访问性将大大提高。
我真的很想知道 VASA-1(及其后继者)将如何改变我们在未来几年沟通、学习和娱乐的方式。数字人脸革命才刚刚开始,未来似乎比以往任何时候都更加现实。

