

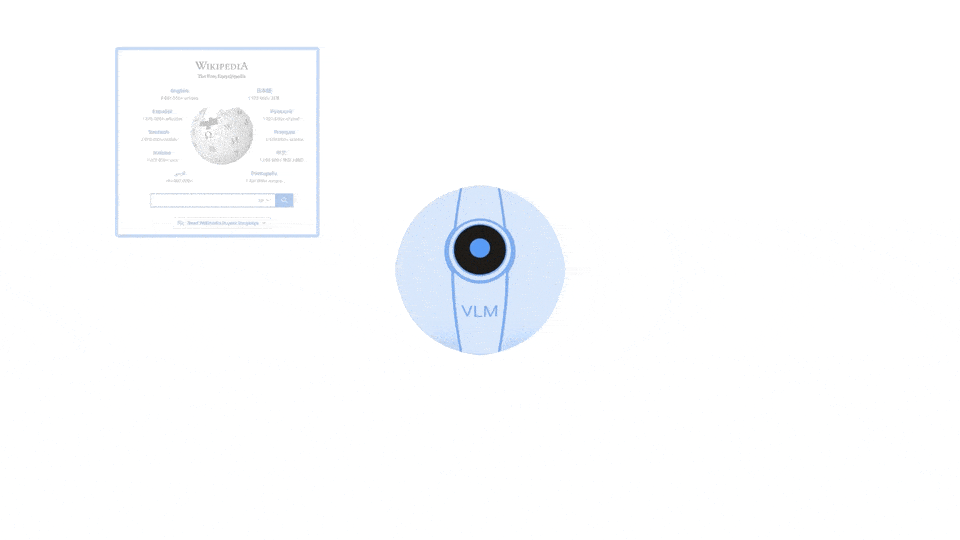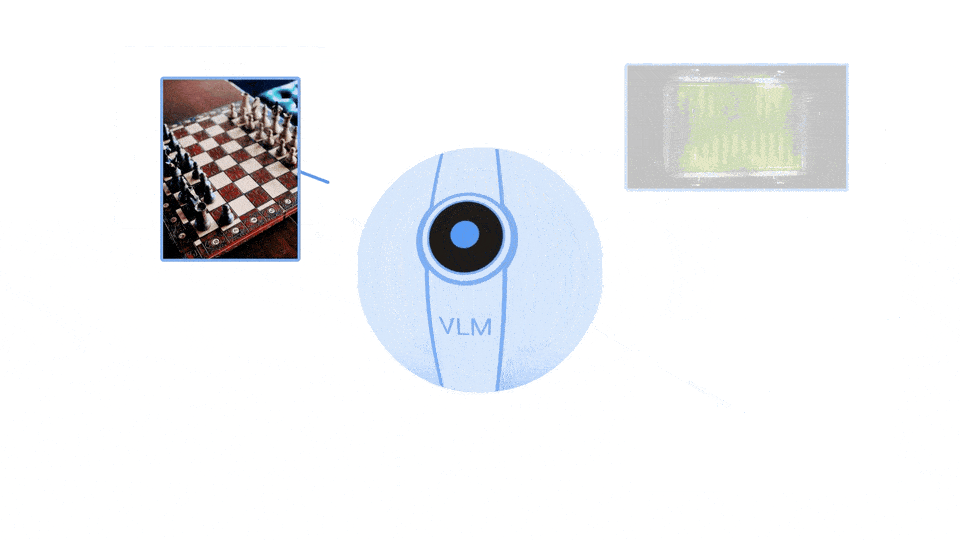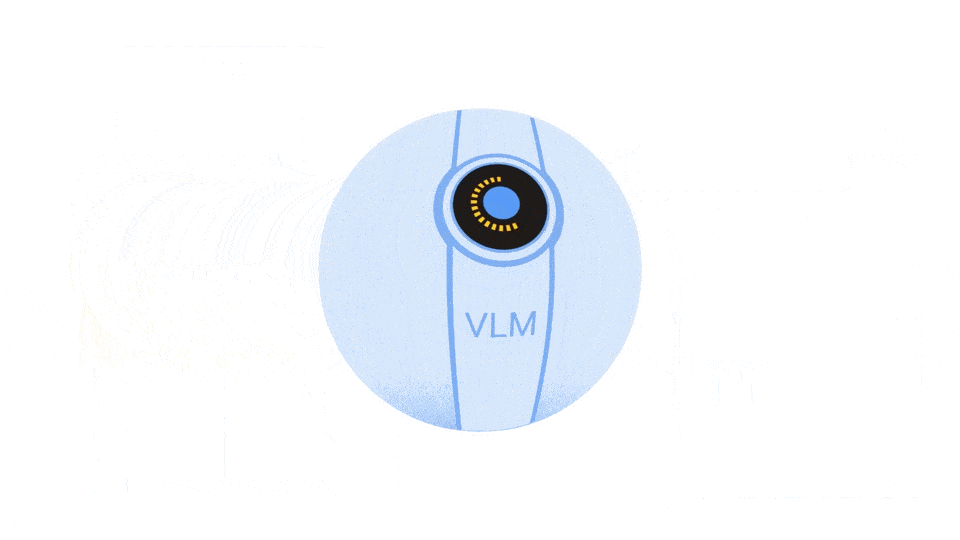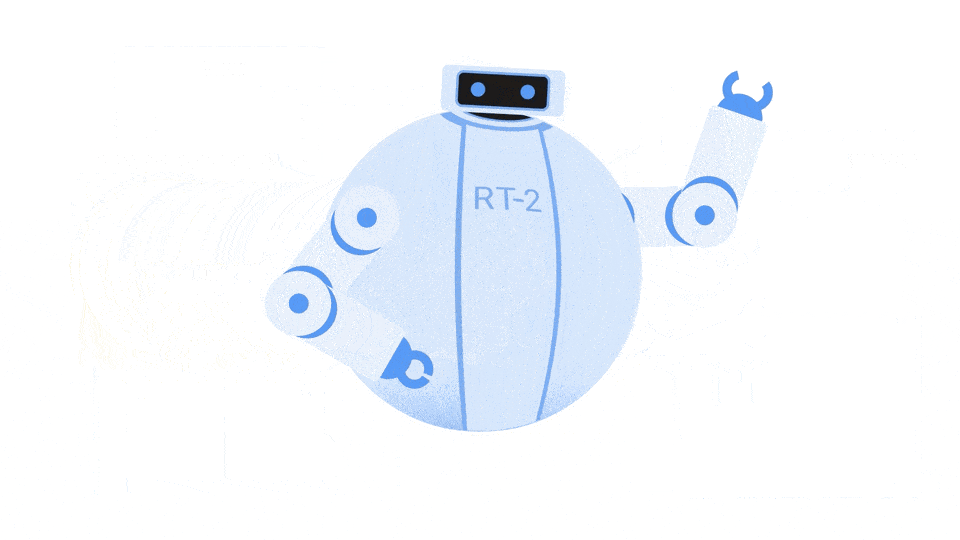
在充满显示器和科技设备的明亮环境中,一个机器人成为主角。它的金属结构会反射光线,但真正的魔法隐藏在它的“眼睛”中。这些眼睛由 DeepMind 的 RT-2 模型提供支持,能够观看、解释和行动。
当机器人优雅地移动时,它周围的科学家们会仔细观察它的一举一动。它不仅仅是一块金属和电路,而是将广阔的网络世界与有形现实结合在一起的智能的体现。

RT-2的演变
近年来,机器人技术取得了长足的进步,但是 DeepMind 它只是将游戏提升到了一个全新的水平。 插图 在纸上 刚刚发布就到了 RT-2。事物?它是一种视觉-语言-动作(VLA)模型,不仅可以从网络数据中学习,还可以从机器人数据中学习,并将这些知识转化为机器人控制的通用指令。
在技术突飞猛进的时代,RT-2 代表了一次重大飞跃,不仅有望彻底改变机器人领域,还将彻底改变我们每天的生活和工作方式。但这在实践中意味着什么?
DeepMind RT-2,从愿景到行动
的模型 高容量视觉语言(VLM) 它们接受过大型数据集的训练,这也使得它们非常擅长识别视觉或语言模式(例如,以不同的语言进行操作)。 但想象一下能够让机器人做这些模型所做的事情。 事实上,别再想象了:DeepMind 正在通过 RT-2 让这一切成为可能。
机器人变形金刚1 (RT-1) 它本身就是一个奇迹,但 RT-2 更进一步,显示出增强的泛化能力以及语义和视觉理解,超越了它所接触的机器人数据。
连锁推理
RT-2 最令人着迷的方面之一是它的链式推理能力。 他可以决定什么物体可以用作临时锤子,或者哪种饮料最适合疲惫的人。 这种深度推理能力可能会彻底改变我们与机器人互动的方式。
最糟糕的是,你仍然可以要求机器人为你准备一杯好咖啡,以恢复一些清醒。
但 DeepMind RT-2 是如何控制机器人的呢?
答案在于他是如何训练的。 事实上,它使用的表示形式与 ChatGPT 等模板所利用的语言标记没有什么不同。
RT-2 展示了惊人的突发能力,例如符号理解、推理和人类识别。 与之前的模型相比,目前的技能提高了 3 倍以上。
与 RT-2 一起, DeepMind 不仅表明视觉-语言模型可以转化为强大的视觉-语言-动作模型,而且还为机器人能够推理、解决问题和解释信息以在真实环境中执行各种任务打开了大门。世界。

现在?
在人工智能和机器人技术将日益成为核心的世界中,RT-2 向我们展示了下一次的进化将不是纯粹的技术,而是“感知”。机器将以我们从未想象过的方式理解并响应我们的需求。
如果这只是开始,谁知道未来会怎样。

