
由工程师和计算机科学家组成的国际团队首次开发出将射频传感与人工智能相结合的技术,以读取嘴唇并识别他的动作。
今天的助听器通过放大周围环境中的所有声音来帮助听力损失的人,这在多种应用中都很有用。然而,在嘈杂的环境中,这些设备的宽广的放大频谱可能会让用户很难专注于特定的声音。例如,与某个人的对话。
这个被称为“鸡尾酒会效应”的问题的一个可能的解决方案是创造“智能”助听器。新设备将传统音频放大与收集额外数据以实现更好性能的第二个设备相结合。

唇读奇点版
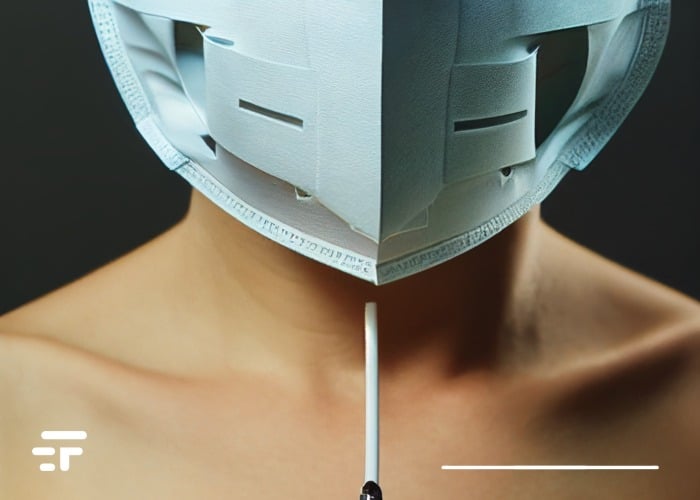
在该杂志今天发表的一篇新文章中 自然通讯 (我在这里链接),格拉斯哥大学领导的团队展示了利用尖端检测技术来读取唇形。他们的系统通过仅收集射频数据来保护隐私,而不利用镜头(因此没有隐私问题,至少在图像上)。
为了开发该系统,研究人员要求男性和女性志愿者先不戴口罩重复五个元音(A、E、I、O 和 U),然后戴上外科口罩。 使用来自专用雷达传感器和 wifi 发射器的射频信号,在闭嘴和发音期间对他们的面部进行扫描。
通过扫描收集的 3.600 个数据样本被用来“训练”机器学习和深度学习算法,以识别特征性的嘴部动作并读取嘴唇,将每个动作与声音相关联。

结果?
系统显示准确率 未戴口罩的嘴唇为 95%,戴口罩的嘴唇为 83%。 感人的。
医生 卡梅尔·阿巴西 该论文的主要作者、格拉斯哥大学的教授解释了所做的工作。 “世界上大约 5% 的人口,即 430 亿人,拥有某种形式的 听力受损。助听器为他们中的许多人带来了改变。收集数据以提高声音放大效果的新技术可能会向前迈出决定性的一步。”
总结:这项研究表明,射频信号甚至 Wi-Fi 信号都可以让您在戴着口罩的情况下读取嘴唇信息。我将这项技术的“负面”用途留给每个人想象,而我只关注积极的方面。
未来的多模式助听器将消除人与人之间的任何差异,使世界上有听力问题的 5% 的人口与所有其他人处于相同的“波长”(必须说)。

